Large Language Models have demonstrated remarkable performance across various tasks, exhibiting the capacity to swiftly acquire new skills, such as through In-Context Learning (ICL) with minimal demonstration examples. In this work, we present a comprehensive framework for investigating Multimodal ICL (M-ICL) in the context of Large Multimodal Models. We consider the best open-source multimodal models (e.g., IDEFICS, OpenFlamingo) and a wide range of multimodal tasks. Our study unveils several noteworthy findings: (1) M-ICL primarily relies on text-driven mechanisms, showing little to no influence from the image modality. (2) When used with advanced-ICL strategy (like RICES), M-ICL is not better than a simple strategy based on majority voting over context examples. Moreover, we identify several biases and limitations of M-ICL that warrant consideration prior to deployment. The code will be made publicly available.
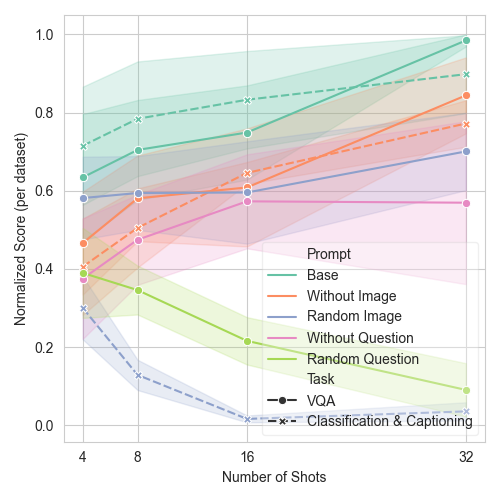
In our research into M-ICL, we looked at how the different modalities (image and text) affect M-ICL behaviour by removing or mixing each modality. Our findings show that image-to-text tasks like captioning and classification are affected significantly when the images are changed. Adding more demonstrations with random images makes things worse, which shows how much the model relies on visual-textual relationships. While text doesn't have much impact on classification, richer text, as in captioning, can improve performance compared to zero-shot. Visual Question Answering behaves differently; modifying or omitting images only slightly reduces its performance. Here, random questions lead to notable performance drops, which suggests that text generally plays a more decisive role in driving the model's decisions. This analysis shows that while both types of information are useful, text takes priority and drives the model's decision-making process.
This graph shows how the M-ICL behaves differently in different setups, with one modality altered. For text-to-image tasks like classification and captioning (shown with a dotted line), we see a big drop in performance when demonstration images are replaced with random ones (blue). In contrast, in VQA tasks, which involve both text and images (shown with a solid line), it's the randomisation of the questions that leads to a drop in performance (green). This pattern backs up the idea that M-ICL is mostly influenced by text. You can find more details on how it performs across different tasks and datasets in the paper.
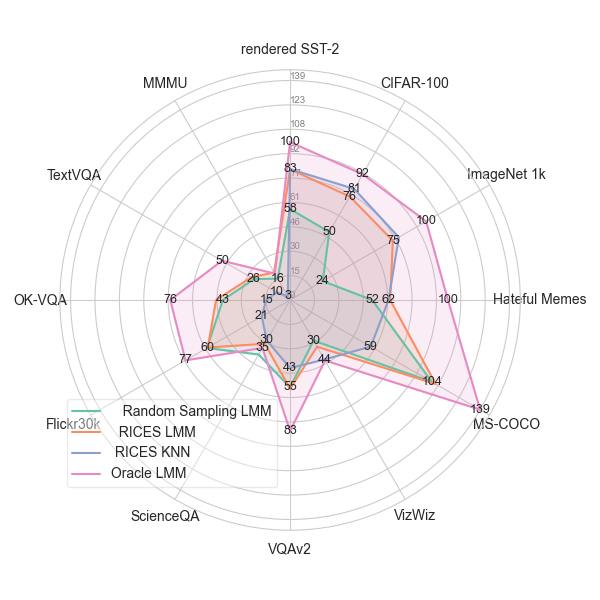
We expanded our study to RICES, which is a method designed to enhance in-context learning through retrieval-based context selection. Our analysis shows that substituting the responses in the context with random ones results in a more significant performance drop using RICES compared to random demonstrations. Having the wrong responses for images similar to the query might push the model to naturally output the wrong response as well. This suggests that images serve as a prior for the demonstrations. We've also looked at how modality affects the method by using RICES with either text or image similarity to find examples that are similar to the ones we've given. We've found that the best similarity metric depends a lot on the dataset we're using and there's no clear answer as to which one to choose for M-ICL models.
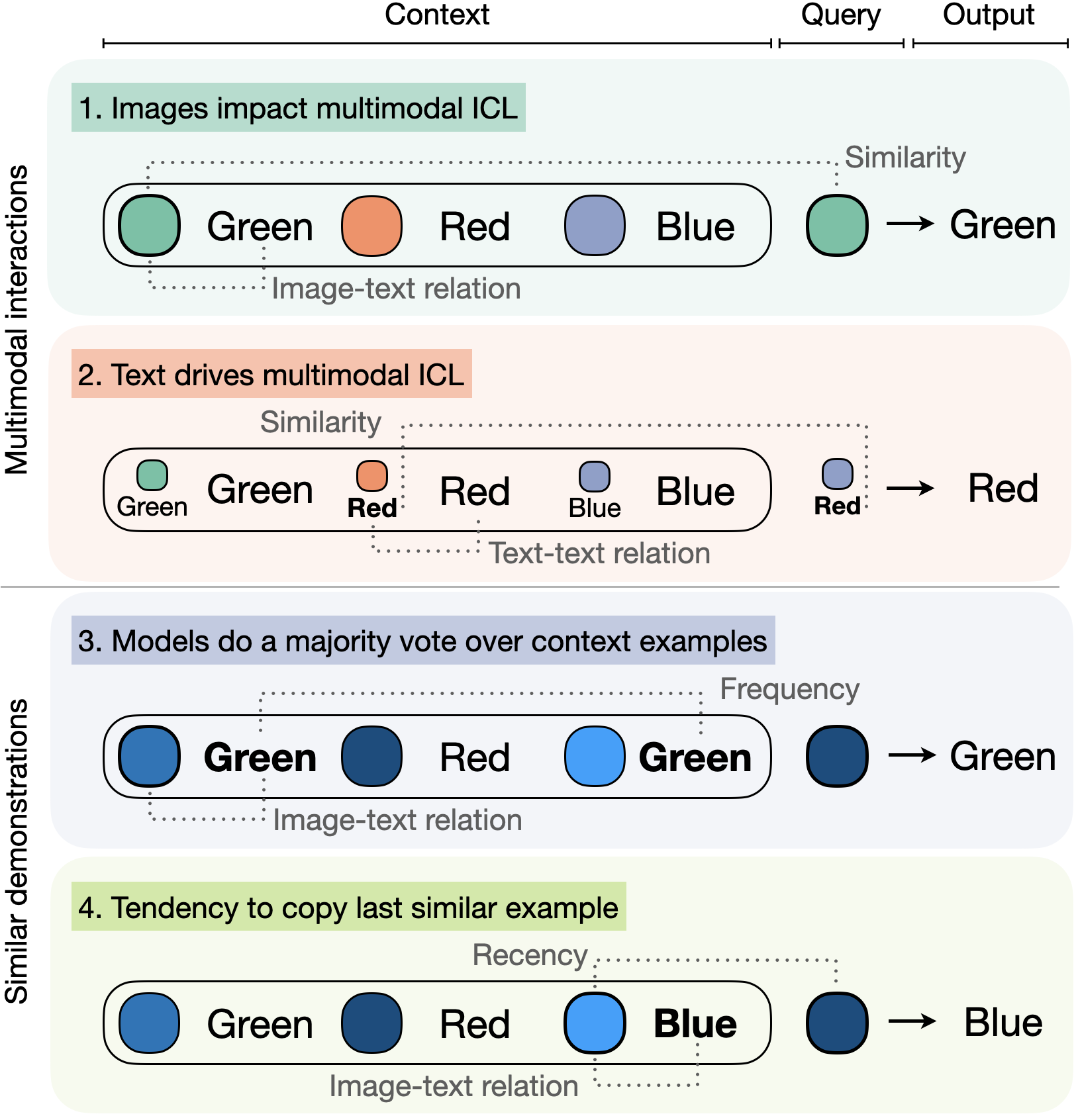
When we looked at M-ICL, we noticed a consistent pattern: demonstrations that closely match the query in terms of input often mirror it in their responses. The closer these responses align with the query, the more accurate the model's generated answers tend to be. This backs up our idea that RICES is effective because it retrieves responses that closely match the target one. But it raises a critical question: Are these performance improvements down to M-ICL using simple shortcuts by repeating similar responses, or are they a result of it learning from closely matched demonstrations? To find out, we look at two potential shortcuts: firstly, that M-ICL is using frequent or relevant responses already in the context; and secondly, that the model may preferentially use the most recent and similar demonstrations, potentially exploiting a recency bias.
We analyse how models base their outputs on the answers that are most common in demonstration contexts and of what performance gains can be attributed to RICES or to M-ICL. We particularly compare M-ICL's effectiveness to that of RICES KNN, whose predicted answer is the most common response from demonstrations sampled with RICES. Our findings show that for classification tasks, RICES M-ICL (orange) struggles to do better than RICES KNN (blue). Even when we make sure that the labels are distributed evenly in the context, this happens. It suggests that M-ICL might just be copying the most common responses, rather than learning.
To address this in open-ended tasks, we compare to Oracle RICES (pink), which takes the demonstration whose responses are closest to the ground truth. This shows that m-ICL can do intelligent soft copy when it's given close responses. However, the used RICES setup doesn't select enough highly similar demonstrations consistently, which limits the potential performance gains.
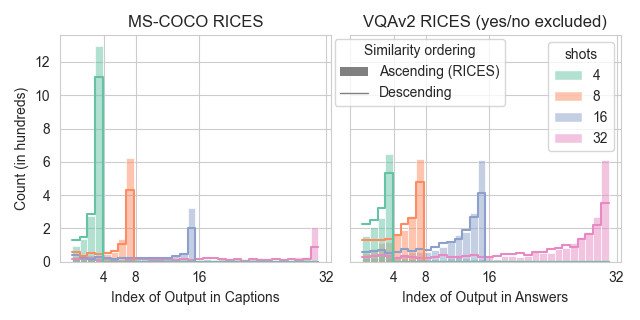
When using similarity-based methods, the recency bias in the M-ICL is clearly evident. Performance not only correlates with the similarity of the demonstrations' responses to the model's output, but also shows a stronger correlation with the most recent demonstrations, regardless of their order of ascending or descending similarity. In addition, the model often produces outputs that exactly match the response of the most recent demonstrations. Although ordering the demonstrations from most similar to least similar reduces the frequency of these exact matches, the underlying trend persists. These observations show that when presented with similar examples, M-ICL tends to reproduce the most recent demonstrations over the most similar ones.
@misc{baldassini2024makes,
title={What Makes Multimodal In-Context Learning Work?},
author={Folco Bertini Baldassini and Mustafa Shukor and Matthieu Cord and Laure Soulier and Benjamin Piwowarski},
year={2024},
eprint={2404.15736},
archivePrefix={arXiv},
primaryClass={cs.CV}
}